
读书笔记,总结。
- 最初的LAMP站点,一台服务器无法满足负载时,首先可以将数据库独立部署,数据库读写分离(当时是2003年,数据库分库分表、memcached概念还并没有被提出),不过很快还是遇到数据库的瓶颈问题,引用原文如下。
“随着访问量和数据量的飞速上涨,问题很快就出来了,第一个问题出现在数据库上。MySQL当时是第4版的,我们用的是默认的存储引擎MyISAM,这种存储引擎在写数据的时候会把表锁住。当Master同步数据到Slave的时候,会引起Slave写,这样在Slave的读操作都要等待。还有一点是会发生Slave上的主键冲突,经常会导致同步停止,这样,你发布的一些东西明明已经成功了,但就是查询不到。另外,当年的MySQL不比如今的MySQL,在数据的容量和安全性方面也有很多先天的不足(和Oracle相比)。”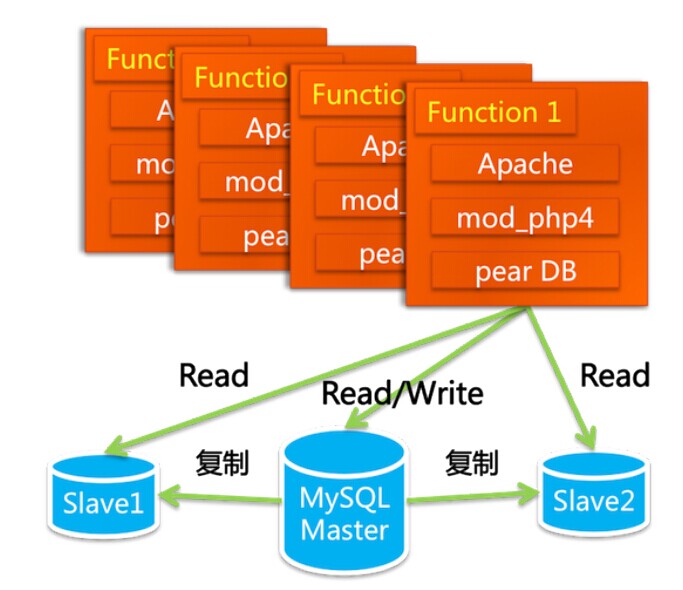
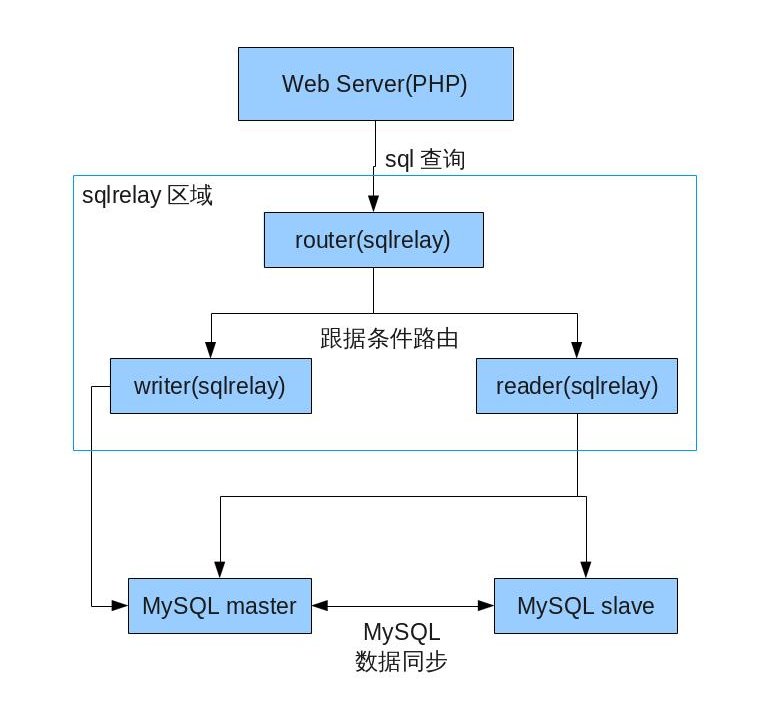
- 通过SQLRelay长效数据库连接池,数据库更换为oracle。之后通过增强硬件提高性能和负载,但是这不太稳定,只维持了差不多半年时间。
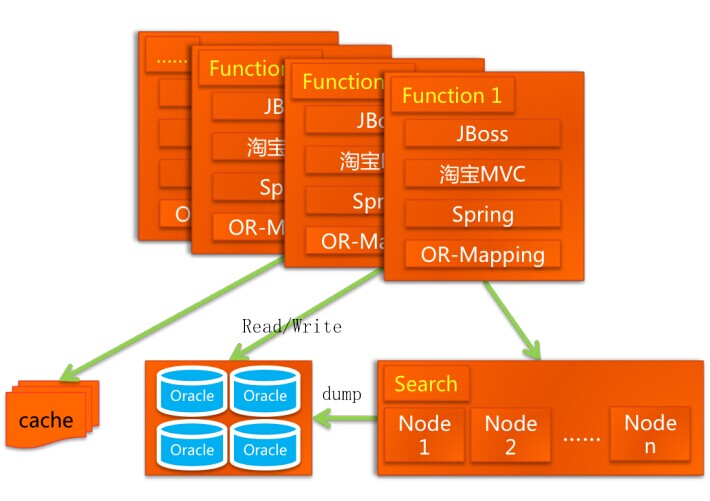
- 业务的持续高速增长,分模块逐步更换为JAVA语言,初期由sun成员架构,后续持续改进后是下图这个样子。java,mvc,spring,ORM,数据分库、缓存、搜索,此时基本软硬件主要是IOE(IBM小型机、Oracle数据库以及EMC存储)网络端有CDN。
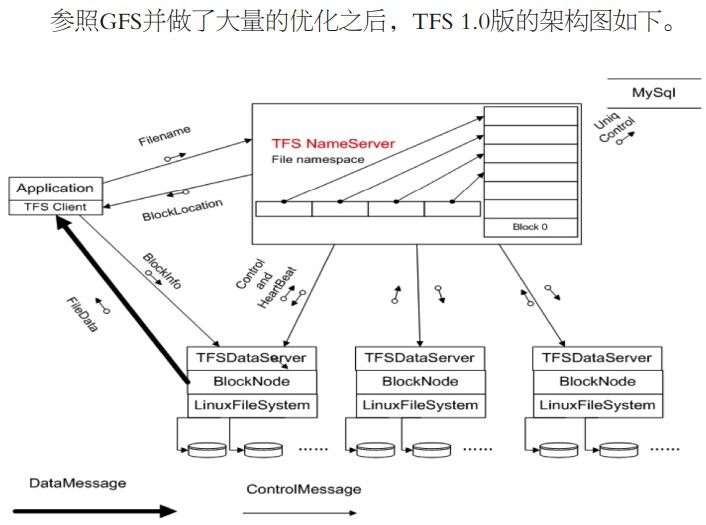
- 之前一直使用的是NetApp公司的文件存储系统,在频临仅限时,综合考虑研发了自己的分布式文件系统TFS(google的GFS改进、taobao file system ),把它应用到了淘宝图片系统,当然并增加了高命中率的一二级缓存,采用实时缩略图通过cpu缓存容量,hash定位索引和排重。图片web系统基于nginx的改进。
- 缓存系统:TBstore,简单的key-value缓存即是Tair的前身,Tair包括缓存和持久化两种存储功能。
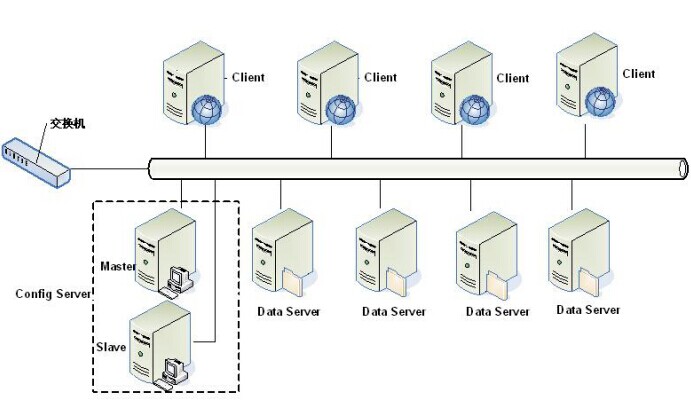
- 分布式时代:oracle连接池已尽极限。开始将velocity、session、分库路由等功能各模块化,业务层分离:交易中心、交易管理、用户中心等等,目标就是把淘宝所有的业务都模块化。关键有两个消息中间件(HSF实时消息和Notify异步消息),解决的问题有负载均衡,替代WebService、Socket通讯。
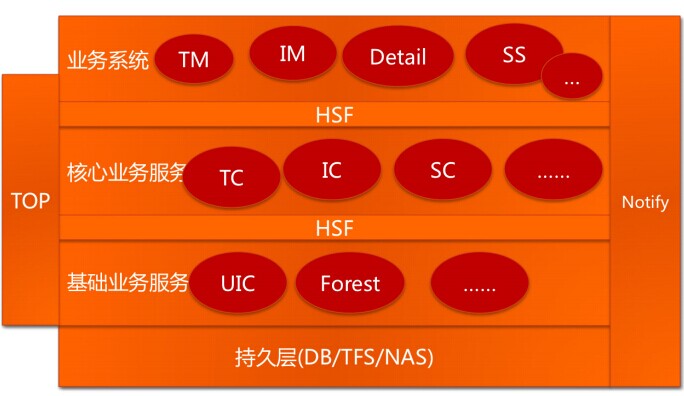
其中,UIC和Forest在上文已说过,TC、IC、SC分别是交易中心(Trade Center)、商品中心(Item Center)、店铺中心(Shop Center),这些中心级别的服务只提供原子级的业务逻辑,如根据ID查找商品、创建交易、减少库存等操作。再往上一层是业务系统TM(Trade Manager,交易业务)、IM(Item Manager,商品业务)、SM(Shop Manager,后来改名叫SS,即Shop System,店铺业务)、Detail(商品详情)。 - 数据库拆分——分布式数据层:TDDL。淘宝最早的数据分开是使用数据路由DBRoute统一管理的,后续是基于Amoeba Proxy的改造。
- Session框架:一个是客户端cookie保存,一个应该在tair的分支。
- hadnoop:一个分布式文件系统(Hadoop Distributed File System),文中对技术没有太多介绍,后续会自行研究。
- 到此为止,应用服务切分了(TM、IM)、核心服务切分了(TC、IC)、基础服务切分了(UIC、Forest)、数据存储切分了(DB、TFS、Tair),通过高性能服务框架(HSF)、分布式数据层(TDDL)、消息中间件(Notify)和Session框架支持了这些切分。一个美好的时代到来了,高度稳定、可扩展、低成本、快速迭代、产品化管理,淘宝的3.0系统走上了历史的舞台。
作者不太厚道~文章最后大篇幅的访谈,最深的体会就是技术会过时的,做东西还是要尽可能站在别人肩膀上,不过最后一句话还是很值得学习的。始终保持对代码的那份单纯的热爱,保持对技术的专注和钻研;别人把工作当工作,他把工作当事业——这就是多隆的程序世界。